New crawl statistics in Google Search Console

«The new Google Search Console tool gives us many clues about the best optimizations for our website.»
We absolutely must celebrate this new tool in Google Search Console, which provides us with extensive information on how Google's robots crawl our website, and what they detect. This new feature significantly enhances the crawl statistics that were offered by the previous tool in Google Search Console. While it may be statistically imperfect, it offers numerous hints on possible optimizations we can apply to our website to encourage Google to visit our site more frequently, crawl our content more effectively, and access our resources with greater ease.
Moreover, this functionality democratizes Google's log analysis. The type of information that Google now provides was previously accessible only to SEO agencies that monitored Google's logs on servers or through complex tools like Screaming Frog. Now, anyone can quickly glance at Google Search Console to understand how Google dissects our site, obtaining quality information on aspects that significantly affect our SEO positioning. It signifies that in the short to medium term, the log analyses that have been conducted until now might become unnecessary.
This new SEO tool is suddenly available to everyone and has been announced by Google on its webmaster’s blog (it's very important to consult this blog in English, as many of Google's contents are not translated, or if they are, it might be too late for us).
How to Find and Take Advantage of Google's New Crawl Statistics
Firstly, it's important to note that the new tool is in the settings, which means that Google has deliberately hidden this new tool, and it's not immediately visible. Google is signalling to us: this is not for everyone; it will only be useful for those deeply interested and focused on technical SEO.
Before moving on to analyse the detailed data, keep in mind that the data provided are from November 1st, meaning there is no historical data, and likely there won't be. Time will tell if more long-term data will be offered later, but for now, it's not available.
We will then analyse the sections found in the report, one by one:
1. General Statistics
Here, we get an overview of the logs that Google makes on our website. We see the volume and evolution over time of total requests, total download size, and average response time. The key is to observe if there are significant changes in the queries Google makes to our site (generally, the more, the better) and the response time Google offers to the spiders. Here, the shorter the response time, the better the experience for Google (and users) on our site, allowing Google more time to explore our site and evaluate our content in greater detail.
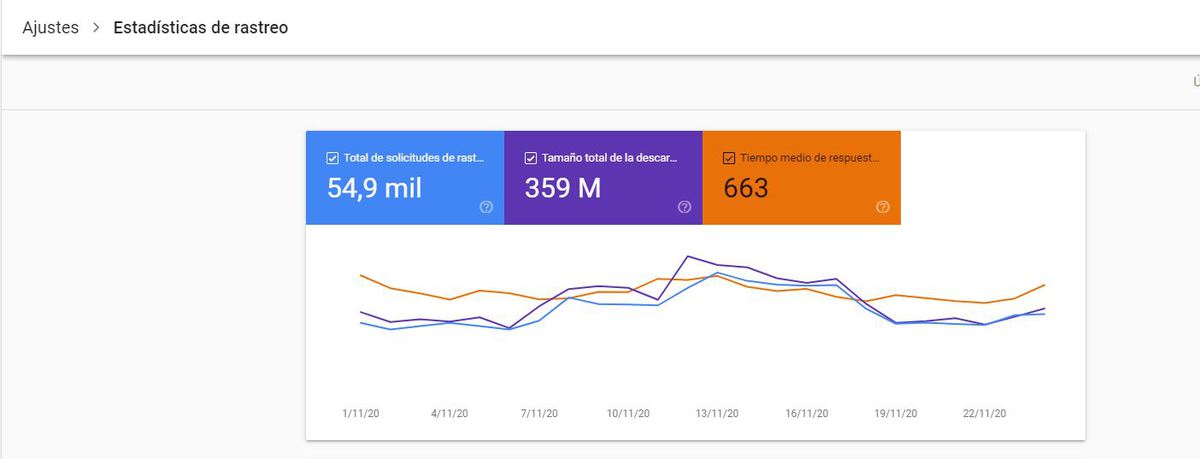
The key is to observe if there are significant changes in the queries Google makes to our site (generally, the more, the better) and the response time Google offers to the spiders. Here, the shorter the response time, the better the experience for Google (and users) on our site, allowing Google more time to explore our site and evaluate our content in greater detail.
2. Host Status
Google generally indicates how our server is responding to its requests. This mainly helps to detect if our server occasionally crashes or becomes saturated. We will see icons with three options in a very graphical and intuitive way:
- Green: The host has been 90 days without showing serious problems. All is well.
- Red: Alarm: Your server has crashed or has given serious crawl issues to Google. You need to take action.
- Soft green: You have taken measures, and the situation is improving. You are now between 1 week and 89 days clean and stable. When you reach 90 days without serious problems, you'll get a green light.
This section doesn't require further detail; just keep an eye on it. If problems recur, you may need to make server adjustments or even change hosting.
Bear in mind that Google awards the traffic light based on 3 metrics, which you can also identify and address separately:
- Access errors to robots.txt
- DNS resolution
- Server connectivity (outages)
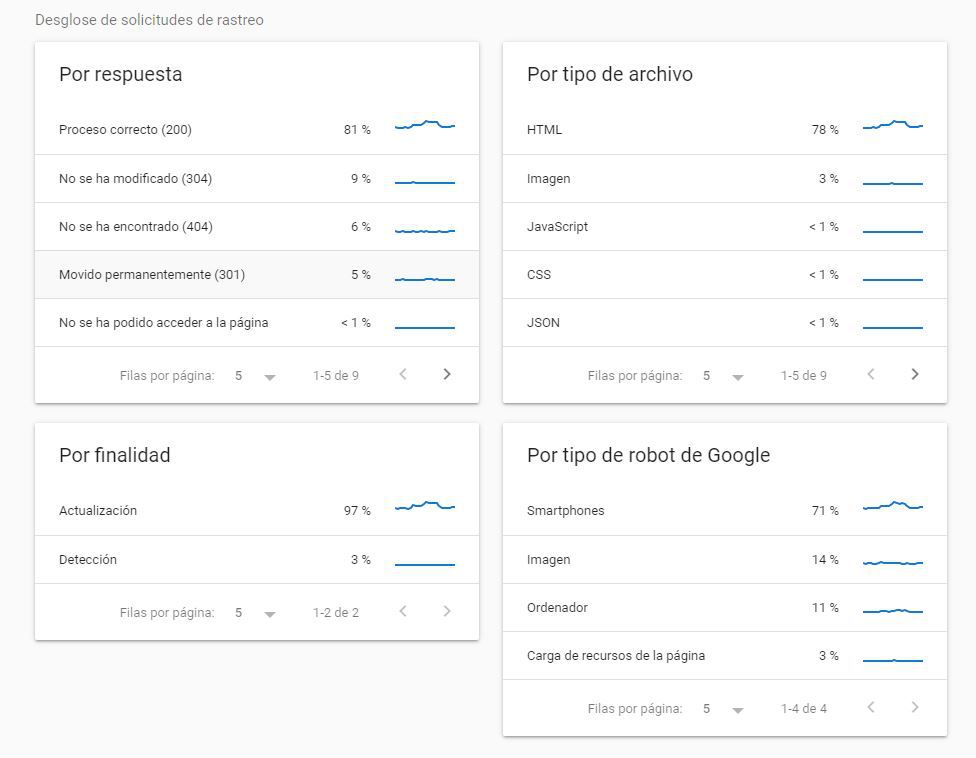
3. Dimensions: By Response
Google indicates, in percentage, what sets of response codes our server has given to Google. Note, the examples we see are samples, not covering all scenarios, but they will serve as an excellent guide. Also, consider that reducing the scenarios will make the examples increasingly reflect reality. In general, responses can be grouped into:
Probably correct requests: 200, 300. Generally, we should always deliver 200 (OK), but some 301 or 302 (permanent or temporary redirects, respectively) are not problematic and can help, as with everything, without overuse.
Suspicious requests: blocked by robots or 404. These responses are not inherently bad; it will depend on what you aim to achieve. If a URL has been blocked by Robots and that was the intent, great. If it wasn't my intention, and I'm hiding relevant content from Google, then it's bad. The same goes for 404 errors; there's no need to obsess over having a website without 404s, as sometimes a page ceases to exist or loses value, then it's out, and it's okay.
Bad requests: these are harmful in any case, and you should observe and repair them. The usual suspects: robots not available, 5xx errors, any 4xx error other than 404, DNS error, DNS not responding, fetch errors, timeout, redirection errors, etc. The fewer, the better.
We reiterate a point made earlier for clarity: the data do not match 100% with the logs; it's a sampling. It allows us to guide improvement actions but won't provide accuracy or excessive detail URL by URL. It's not meant for that, although you might not need it for that purpose.
4. Dimensions: By File Type
Google differentiates resources by file types (HTML, images, JS, CSS, JSON, etc.). While we already knew this, we can now see what percentage of each type of resource is crawled. Generally, and pending how aspects like HTTP2 evolve, the more HTML crawling, the better, as it's what Google reads fastest and will most impact our SEO.
There's a certain black hole in two sections you'll observe: other file types (there's a bit of everything here, and hopefully, over time they'll separate queries of sitemaps or robots, for example), and error requests. There might be room for improvement here, but even so, this information already provides a lot of value and is infinitely better than what we previously had.
5. Dimensions: By Crawl Purpose
This section is very brief and straightforward, and it might seem so minor that we could gloss over it. And NO. Google distinguishes between detection (new URL) and update. This implies that likely some robots are dedicated to detecting new content on the net, and others to detecting improvements and updates. And most importantly: we know that for Google, there are two crawl queues: one for new things and one for updates. The first moves faster, and we're interested in promoting it. The more new content, the more crawl budget. That means we need to generate new content so that Google visits our website more often and crawls it more. If we already knew this, it becomes much more important now that Google no longer allows us to manually send URLs for indexing. Hint: if I've updated content that's somewhat old, and I want Google to pass by soon, how about linking it from the main page or from new content?
6. Dimensions: By Robot Type
We know that Google has a robot for smartphones, one for Google Ads, one for loading page resources, and possibly others. This new report can guide us on how optimized our page is for mobile (mobile-first indexing) or how long it takes to load resources on the page. Regarding this topic, there might be something you don't know, or if you do, it never hurts to refresh: for a URL, Google first passes quickly and obtains the HTML, and later returns to analyse heavier resources that are harder to render: CSS, JS, etc., to see the web as the real user does. Here, it will be very important to streamline and unify the loading of these types of resources as much as possible and prevent some of these from blocking the rendering to Googlebot. For now, in this field, websites made with technologies like React continue to be penalized compared to the king PHP, at least for the moment, although there are signs that this may change in the future.
Consejo: valida tu propiedad en Search Console como dominio
In Google Search Console, you have the option to register a single version of our domain (let's say http://mywebsite.com), or the entire domain, with all its subdomains and various protocols. If you have the chance, it's always better to validate, at least at the domain level. With the new crawl statistics tool, you can see a delight: the status of the different hosts of the web, which will give you clues about queries by subdomain, if we have made a migration towards www or vice versa we will see to what extent Google has already carried out its migration process, or well, as the case we illustrate in the capture, we realize that Google is making requests to subdomains that we didn't even know existed, which can't be good.
Conclusions on the new crawl stats from Google Search Console
With all the precautions that must be taken with something new, and always being cautious, what we have seen in the first days of its operation allows us to state the following: it's very good. It's very comprehensive information, finally easily accessible to anyone. It advances the world of SEO in two directions that go hand in hand: greater democratization of SEO optimization, which will no longer be only within the reach of agencies or professionals with significant resources; and greater transparency from Google regarding how it analyses and values our websites. Google has fewer and fewer secrets from us, as its officials want, and we can only celebrate this. The secret of SEO is not witchcraft or anything similar; it's very simple: read a lot and work hard. There's no other recipe for success in SEO, at least in the medium term.
PS: If you want more details about this tool, you can consult Google's documentation.




